Clearing Polluted Data Streams – Feeling the Pain
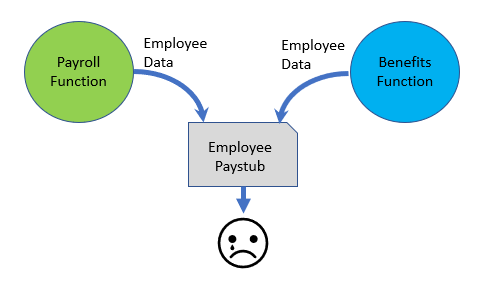
In complex transactional systems, understanding the life cycle from inception to retirement of critical data is an essential step is identifying, correcting and preventing data conflicts and subsequent unwanted consequences. In a classic systems integration case, a major company reported a high error rate on any given payroll run that led to unhappy employees, unhappy managers, and expensive remediation. The causal event was the integration of its payroll and benefits systems. The detailed origins of the problem were the result of several factors:
- Data about the employee was stored and managed on multiple systems by two separate organisations.
- Both systems collected data on the number of dependents of the employee using the same field in the payroll database. However, the usage of that data was different between the Payroll and Benefits functions as the number of dependents for tax withholding purposes and for health insurance benefits was typically different.
- Besides the structural factors above, documentation on the relevant data structures, including table and column definitions, was incomplete or missing.
- The repetitive flow of data, collection, processing and output was not documented and was subject to different understandings and remediation steps depending on geographic and department variations.
Polluted, or compromised data can occur anywhere along the data life cycle. In this and future posts, some key vulnerabilities and strategies for addressing those will be discussed.
Vulnerability – Inception Phase:
In the employee paystub example, the company initially defined the characteristics or attributes of the concept of employee that were considered important about which to capture data. One difficulty was the evolutionary nature of this definitional phase. Payroll requirements were defined before benefits requirements and by different functional groups. Additionally, the definitions of employee attributes, especially the number of dependents, was not shared. As attempts to operate this integrated system progressed, the Benefits function spawned off-line local databases to keep track of individual employee variations. The negative results of this action were the creation of different versions of the concept of employee (variations in the metadata), as well as varying instances of the employee records themselves.
The conceptual solutions for this example were:
- Requiring definitions for all critical data elements derived from the company’s business requirements;
- Modifying the data architecture to accommodate both Payroll and Benefits usage; and
- Instituting access restrictions for data entry during the operation of the combined payroll/benefits process.
A logical depiction of the metadata changes could look like the following:

It can be a painful, repeating occurrence to organisations that fail to recognise the need to collect, document, rationalise, organise and communicate business and technical requirements. From a data management perspective, the methods and tools that can be used are numerous, including glossaries, conceptual and logical data models, physical data models as well as data management practices Applying these through the business definition, data architecture and construction, and operation and maintenance phases of a company’s information systems can and will lead to smoother data management operations and higher data quality.
Coming soon … Data Technical and Project Management: Clearing Polluted Data Streams – Flying Blind.